Engineering Systems That Fail Less and Perform More: Storage Reliability, Durability, and Data Protection
Storage Reliability, Durability, and Data Protection are not purely IT concerns — they are business levers. For architects, developers, and their respective management teams, the design choices you make around durability, availability, and recoverability translate directly into customer trust, operational continuity, regulatory compliance, and ultimately net profit. This post ties core storage engineering concepts to economic outcomes and the practice of reliability engineering, with practical guidance. In our previous post, “Practical Storage Choices for System Design: Performance, Durability, and Cost”, we discuss storage architecture as it relates to performance optimization during system design. In this post, we focus on economic outcomes and using practices such as reliability engineering throughout the entirety of the storage systems lifecycle. Before we begin, we’ll dissect storage systems and touch on metric signals that are critical to measuring their performance.

Durability vs.
Availability
System capabilities and their associated system types.
Durability vs. Availability
Durability and availability are distinct but complementary objectives in the design of storage systems. Durability describes the long-term guarantee that data will not be lost or corrupted — the persistence and integrity of stored information over time, even in the face of hardware failures, media degradation, or catastrophic events. Availability focuses on the ability of the system to serve read and write requests when needed — the responsiveness and operational accessibility of data at any given moment.
The image to the right, contrasts durability and availability in storage systems. On the left, durability is depicted as protecting data against bit rot, disk/SSD/controller failures, latent sector errors, software corruption, and site disasters, measured as a probability over time (e.g., “eleven 9s”) and achieved with techniques like replication, erasure coding, end-to-end checksums, immutable writes, scrubbing, versioning, and durable metadata. On the right, availability focuses on minimizing downtime and ensuring timely access despite device/network failures, crashes, overloads and maintenance. This is measured as uptime percentage or mean time to recovery and delivered through leader/consensus routing, retries, timeouts, load balancing, failover, caching, QoS and fast recovery.
Why Distinguishing Between Them Matters
Requirements and architecture: Durability determines how data is protected against loss over long periods; availability determines how systems are built to tolerate transient and persistent outages without interrupting service. Designing to meet an SLO for availability is different from meeting an SLA for durability.
Cost and operational focus: Investments in durable storage (additional replicas, scrubbing) increase capital and operational costs differently than investments in high-availability infrastructure (redundant networking, faster failover, autoscaling).
Incident response and testing: Durability-focused tests validate recovery from rare catastrophic failures and silent corruption; availability-focused tests exercise failover, load spikes, and network partitions.
The image below displays the tradeoffs between the two. Durability’s extra copies and write amplification can raise latency and cost and impact availability, while availability optimizations (caching, relaxed consistency) can expose windows of non-durability, and synchronous replication/strong consistency can improve durability at the expense of availability during partitions.
Durability often requires additional storage and write amplification (e.g., multiple copies, coding), which can increase write latency or cost and indirectly affect availability if not designed carefully. Availability optimizations such as aggressive caching or relaxed consistency can improve responsiveness but may expose windows where recent writes are not yet durable. Strong consistency and immediate durability (synchronous replication) can reduce availability during partitions; relaxing one can improve the other depending on requirements.
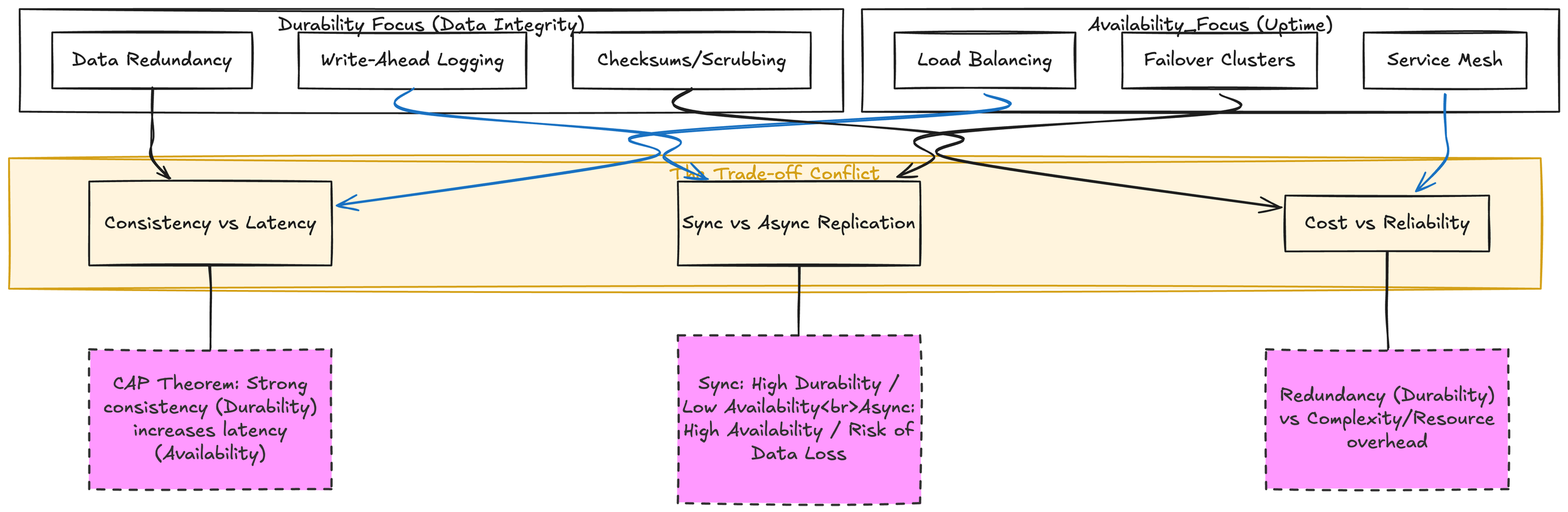
Durability and Availability Trade-offs.
In practice, a robust storage system balances both areas. It uses durability mechanisms to ensure data survives faults while engineering availability mechanisms to keep that data accessible when applications need it. Clear requirements and explicit SLOs for durability and availability guide appropriate choices in redundancy, consistency, latency targets, and operational procedures.
Definition and Business Impact
Durability: the probability that data will not be lost over time. A durability figure (e.g., 11 nines) expresses expected data loss frequency. Durability protects long-term value — lost data can mean regulatory fines, lost revenue, or irrecoverable customer records.
Availability: the probability that data is accessible when requested. Availability impacts customer experience and revenue continuity — outages directly affect transaction volumes and SLA penalties.
Trade-offs
High durability does not automatically mean high availability. Systems can be extremely durable (no data loss) but temporarily unavailable (maintenance, transient failures).
Economically, high availability reduces immediate revenue loss and churn; high durability reduces long-term business loss and legal/regulatory costs.
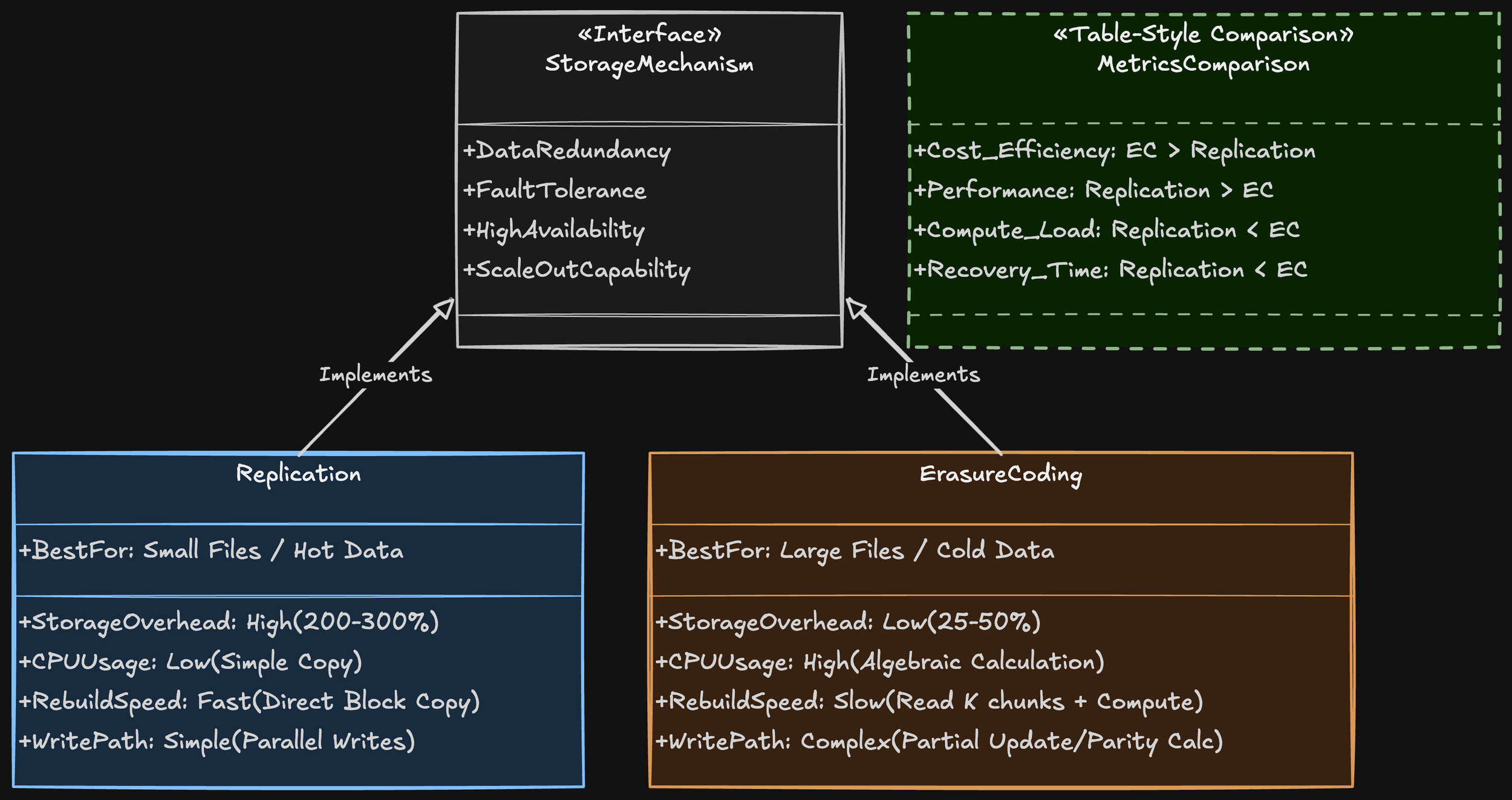
Replication vs. Erasure Coding
Overview Replication and erasure coding are two fundamental techniques for data protection and availability in distributed storage systems. Both achieve durability and fault tolerance by creating redundancy, but they differ in how redundancy is produced, the storage overhead involved, performance trade-offs, and operational complexity.
How They Work
Replication: Stores multiple full copies of the same data across different nodes or locations. Common configurations are 2x, 3x, etc., indicating the number of complete replicas.
Erasure coding: Splits data into k data fragments and generates m parity fragments using coding algorithms (e.g., Reed-Solomon). Any k out of the k+m fragments are sufficient to reconstruct the original data.
Similarities
Fault tolerance: Both enable data recovery after node or disk failures by relying on redundant information.
Availability improvement: Both increase data availability by distributing pieces or copies across multiple failure domains (racks, zones, regions).
Network and placement considerations: Both require careful placement policies to avoid correlated failures and to ensure fragments/replicas are on separate failure domains.
Use in distributed systems: Both are widely used in cloud and large-scale storage systems as primary mechanisms for protecting objects, blocks, or files.
When To Use Each
Replication is preferable when:
Low-latency reads and simple operational model are primary requirements.
The system needs very fast rebuilds and minimal compute overhead.
Data set size and storage cost are moderate and acceptable for full-copy redundancy.
Geo-replication (serving users from regional replicas) is important.
Erasure coding is preferable when:
Storage efficiency and reduced long-term storage costs are critical (large cold or warm data sets).
Read/write access patterns are mostly large, sequential, or read-dominant, minimizing small-write penalties.
The system can tolerate higher rebuild bandwidth/latency or uses optimized repair techniques (local reconstruction codes, hierarchical repair).
The environment supports the CPU/network resources needed for encoding/decoding and rebuilds.
Hybrid Strategies and Optimizations
Many systems mix methods. They replicate frequently accessed (“hot”) data to maximize speed, while using erasure coding for less-accessed (“cold”) or capacity-focused data to conserve storage. Advanced erasure codes — such as local-reconstruction and regenerating codes — reduce repair bandwidth or accelerate local recovery, but they introduce additional fragments and greater system complexity. Tiering and dynamic placement move data between replication and erasure coding according to evolving access patterns and service-level agreements (SLAs).
Within the design phases, placement must avoid correlated failures, so replicas and erasure-code fragments should be distributed across racks and availability zones. Choose methods according to SLAs to meet required durability and availability targets, balancing performance, storage efficiency, and operational complexity.
RPO / RTO, Backups, Snapshots, Continuous Replication
Recovery Point Objective (RPO) and Recovery Time Objective (RTO) are foundational metrics in data protection and disaster recovery planning. RPO defines the maximum acceptable amount of data loss measured in time — how far back in time you must be able to restore data after an outage. RTO specifies the maximum acceptable duration of downtime — how quickly systems and services must be restored to meet business requirements. Together, RPO and RTO drive architecture, operational procedures, and investment decisions for resilience.
Supporting each, Backups are the traditional, scheduled copies of data and system state stored separately from production environments. They provide point-in-time restorations and are a cost-effective way to meet moderate RPOs and RTOs. Backup strategies vary by frequency (full, incremental, differential), retention policies, and storage media (on-premises, offsite, cloud). Backups are essential for protecting against data corruption, accidental deletion, ransomware, and long-term archival needs, but they typically incur longer RTOs and coarser RPOs compared with more continuous approaches.
On the other hand, Snapshots are rapid, typically storage-layer or hypervisor-based point-in-time images of data volumes or virtual machines. Snapshots enable quick rollback to recent states with minimal performance impact and are well-suited to short-term retention, testing, and rapid recovery scenarios. While snapshots can reduce RTO significantly and improve RPO granularity, they are not a substitute for long-term backups because they often share underlying storage and can propagate logical corruption or ransomware if not managed and replicated properly.
Continuous Replication (including synchronous and asynchronous replication, and near-continuous data protection) streams writes from production to a secondary site or storage target in near real time. Synchronous replication guarantees zero or minimal data loss (low RPO) by acknowledging writes only after they are committed on both primary and secondary systems; it is typically limited by distance and latency constraints. Asynchronous replication allows greater geographic separation and lower latency impact at the cost of potential data loss measured in seconds to minutes. Continuous replication enables the lowest RPOs and, when combined with automated failover orchestration, the fastest RTOs.
Selecting the appropriate mix of backups, snapshots, and continuous replication requires mapping business-critical workloads to their required RPO and RTO targets, understanding cost and operational trade-offs, and designing isolation and verification mechanisms (air-gapped or immutable copies, regular restore testing, and monitoring). A resilient strategy often layers these techniques: frequent continuous replication or snapshots for mission-critical systems to meet aggressive RPO/RTOs, complemented by periodic immutable backups for long-term retention and protection against logical corruption or ransomware.
Practical Patterns
Multi-tier protection: Continuous replication for low-RPO critical systems + immutable off-site backups for ransomware and corruption protection.
Decide by cost-benefit: Model lost revenue per minute/hour vs incremental cost of replication or faster restore.
Testing Data Recovery: Exercises and Tools for Storage Systems
Test Recovery-only confidence is theoretical until exercised. Regular, deliberate testing reveals procedural gaps, flaky tooling, undocumented dependencies, and assumptions that inflate Recovery Time Objective (RTO). Tests validate not just that backups exist, but that personnel, processes, and automation perform under real conditions.
Practical Principles Before You Start
Define objectives: full-site restore? single-LUN recovery? object-store item retrieval? Choose measurable success criteria (RTO, RPO, data integrity checks).
Scope and impact: classify tests as non-disruptive (read-only, snapshot-based) or disruptive (failover, restore to production-like hosts). Schedule windows and communicate.
Baseline and metrics: capture pre-test performance, restore times, error rates, manual steps/time, and checklist completion.
Automate where possible: repeatability reduces human error and provides comparable metrics over time.
Retrospective and remediation plan: every test ends with an action list, owner, and deadline.
Types of Exercises (Concrete Examples)
Tabletop Exercises
Validates decision-making, runbooks, escalation paths, and communications without touching systems.
Example scenario:
Trigger: A major region loses storage fabric connectivity.
Participants: storage SME, backup SME, app owners, SRE, incident commander.
Flow: Walk through detection → declaration of DR → restore priority list → credential access → communication plan.
Deliverable: Updated runbook with clear “who does what” and checklist of pre-reqs (e.g., privileged keys available, out-of-band console access).
Practical tip: Use a simple timeline wall (virtual or physical) and a scribe to capture assumptions and unknowns.
Simulation / Playbook-driven Restores (non-disruptive)
Validates restore scripts and toolchains using copies or sandbox targets.
Example scenario:
Restore a production database backup to an isolated recovery host using the same automation used for production restores.
Provision isolated recover host or namespace (cloud VPC, bare-metal lab).
Run standard restore automation (snapshot export → transfer → import → consistency checks).
Execute application-level verification: run a small read-only query set, checksum verification, and schema checks.
Metrics to collect: time for each stage, errors, manual interventions.
Practical tip: Keep a “gold” validation script that checks key tables/objects and a hash list of critical files.
Full Failover / Disaster Recovery (disruptive / scheduled)
Validates end-to-end failover to a secondary site, including storage re-mounts, IP routing, and app-level recovery.
Example scenario:
Complete site failover to DR data center or cloud region.
Initiate failover according to playbook.
Reconfigure DNS/load balancers.
Attach restored volumes; perform integrity checks; bring up services.
Run smoke tests and performance sanity checks.
Success criteria: RTO met, data intact, services functional.
Practical tip: Do at least one full failover annually under controlled conditions; use feature flags to reduce user impact.
Component-level Chaotic Testing (fault-injection)
Tests system robustness under storage-specific faults (IO latency spikes, node failure, degraded RAID).
Example scenarios:
Inject artificial IO latency on storage controllers and observe application behavior.
Simulate a failed disk or controller and validate RAID rebuild and degraded performance mitigation.
Tools: fio for IO stress, tc/netem for network latency, vendor simulators for controller failures.
Practical steps:
Run stress during off-peak: monitor metrics.
Validate automatic failover and rebuild processes.
Measure impact on RTO/RPO and operations runbook adequacy.
Restore-to-cloud / Cross-region Restores
Ensures backups can be restored to an alternate cloud or region with different storage semantics.
Example scenario:
Restore on-prem backups to a cloud object store and spin VM instances there.
Export backup to cloud-compatible format or copy object data.
Rehydrate volumes or objects in cloud.
Validate application compatibility and networking.
Practical tip: Maintain tooling to translate storage formats (snapshots → block volumes, object manifests) and test regularly for API/permission changes.
In an era where data in transit is critical in every strategic decision we make, transaction and service, storage reliability and comprehensive data protection are not optional—they are foundational to operational resilience and trust. Adequate and robust modern test practices, well-defined frameworks and purpose-built tooling are essential to uncover failure modes, assure recoverability and validate performance under real-world pressure. At A.M. Tech Consulting we translate these principles into tailored system designs, pragmatic testing roadmaps and deployable automation that reduce risk and maximize uptime. If you’re ready to harden your system’s estate and future-proof your data strategy, schedule a consultation with our experts and let us architect the reliability your business demands.