SRE Readiness Assessments: How SRE Maturity Drives Revenue and Reduces Cost
Site Reliability Engineering (SRE) is more than ops practices and tooling — it’s a measurable business capability. When organizations assess SRE maturity across key domains they reveal direct levers for revenue growth, cost reduction, and measurable ROI. In this article, we translate the pillars of SRE readiness into business outcomes, link them to profit metrics, and show how a focused maturity assessment turns reliability practices into dollars and cents. Assessing the state of SRE readines among your team or organizations, provides layers of observability to ensure business strategy is in alignment with internal technical strategy.
Production Readiness — Prevent outages, protect revenue
Production readiness ensures systems are designed, tested, and provisioned to operate reliably at expected loads. It includes capacity planning, failover design, and runbook completeness.
Why it matters to the bottom line
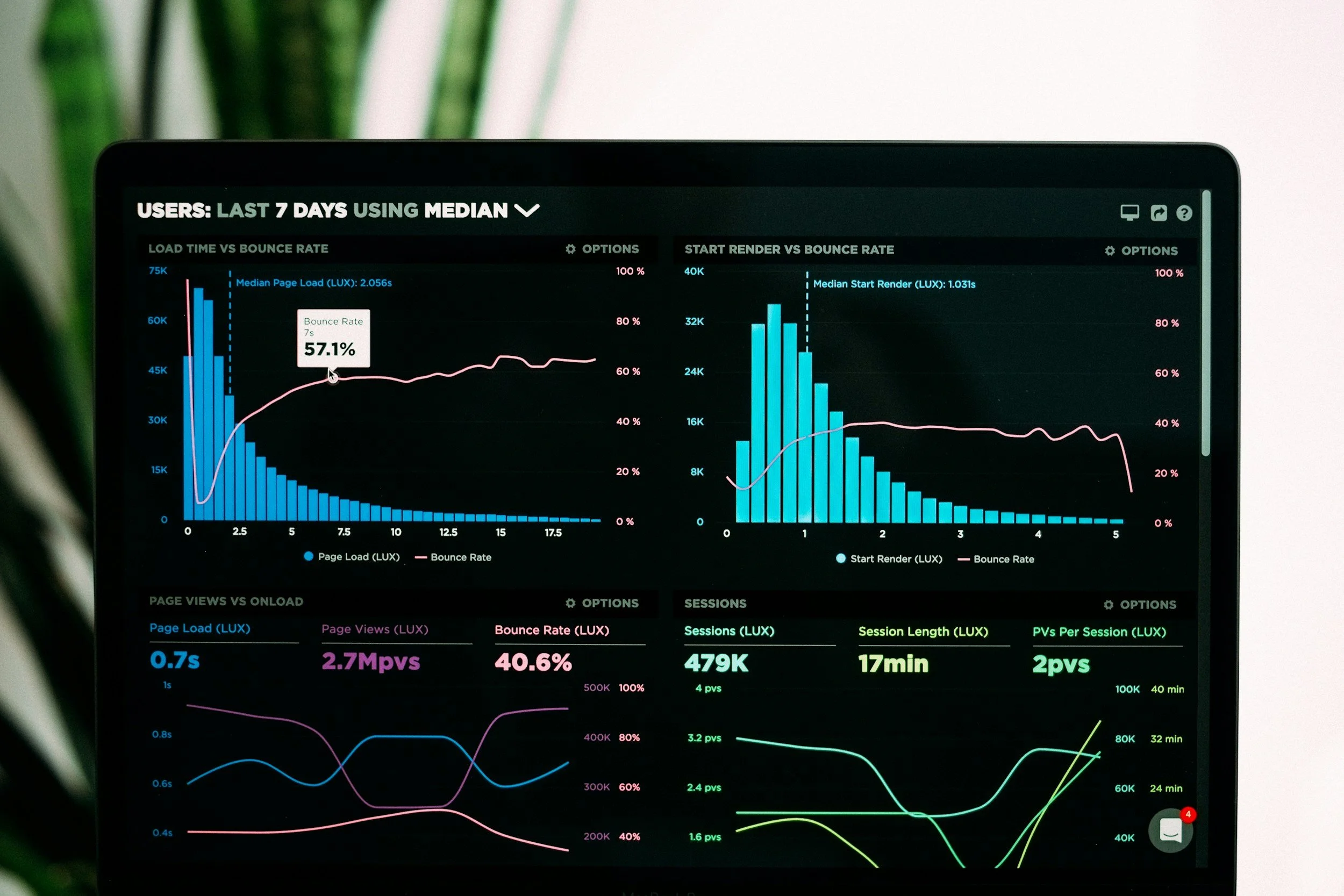
Outage cost reduction: Estimate cost per minute of downtime (lost revenue + remediation + SLA penalties). A single high-severity outage can cost thousands to millions; improving readiness reduces frequency and duration.
Customer retention: Reliable services lower churn rate. Even a 1% reduction in monthly churn can translate to significant ARR uplift over time.
Profit Metric Examples
Mean Time Between Failures (MTBF) improvement → reduced lost-revenue minutes × average revenue per user (ARPU).
SLA penalty avoidance → direct reduction in refunds/credits.
Our maturity assessment quantifies readiness gaps, prioritizes fixes that yield the largest reduction in expected outage cost, and converts technical risks into projected financial impact.Development Practices — Reduce defects, accelerate delivery
Best practices in code review, automated testing, CI pipelines, and deployment safety make reliability part of development.
Why it matters to the bottom line
Lower defect rate reduces post-release firefighting costs and accelerates time-to-market for revenue features.
Increased release velocity enables faster product experiments and quicker monetization of new initiatives.
Profit Metric Examples
Defect escape rate reduction → fewer incident-hours × engineering hourly cost.
Feature cycle-time reduction → faster feature revenue realization (months shaved off time-to-market).
Our maturity assessment measure where practices are brittle and estimate engineering-hours reclaimed by automating or improving workflows. Those hours can be reallocated to revenue-generating work.
Capacity Planning — Scale predictably to capture demand
Predictive capacity planning avoids underprovisioning (performance loss) and overprovisioning (wasteful spend), aligning infrastructure with demand forecasts.
Why it matters to the bottom line
Prevent lost transactions during peak demand.
Optimize cloud spend to lower operating expense (OpEx).
Profit Metric Examples
Conversion uplift during peak periods → prevented revenue loss (% of sessions × avg order value).
Infrastructure cost savings → reduced monthly cloud spend (rightsizing + autoscaling).
Our assessment identifies forecasting accuracy, headroom policies, and auto-scaling gaps. You can then model revenue preserved by eliminating capacity-related failures and cost reductions from rightsizing.
Test & Release — Ship with confidence, minimize rollback costs
Robust test suites, canary releases, feature flags, and progressive rollouts reduce the blast radius of changes.Why it matters to the bottom line
Fewer rollbacks and hotfixes cut engineering firefighting hours and customer-impact time.
Higher release reliability increases customer trust and conversion over time.
Profit Metric Examples
Reduction in rollback events → saved engineering-hours × cost per hour.
Improved feature uptakes due to fewer regressions → incremental revenue from stable releases.
Our maturity assessment scores release safety controls and projects the reduction in post-release incidents and their associated costs, turning technical investments into expected financial returns.
Incident Response — Recover fast, learn faster
A practiced incident response process — detection, escalation, remediation, and postmortem learning — minimizes downtime and repetitive failures.
Why it matters to the bottom line
Faster recovery reduces Mean Time To Recovery (MTTR), directly shrinking outage cost.
Post-incident fixes prevent recurrence, compounding savings over time. Profit metric examples.
MTTR reduction → fewer revenue-impact minutes × ARPU.
Reduced incident recurrence → lowered annual incident count × average incident cost.
Our maturity ssessment reveals response bottlenecks and estimate time-to-recovery improvements, which you can convert into avoided revenue loss and lower incident-handling expense.
Monitoring & Observability — Turn data into proactive action
Comprehensive metrics, tracing, logs, and alerting that provide actionable, business-aligned signals.
Why it matters to the bottom line
Early detection prevents user-facing problems and reduces churn.
Business metrics in observability enable targeted remediation that protects high-value flows.
Profit Metric Examples
Percentage of incidents detected proactively → avoided customer impact × ARPU
Continuous Improvement: Turning SRE Maturity into Measurable Profit
Reliability isn’t a checkbox — it’s a continual engine for growth. When Site Reliability Engineering (SRE) is treated as an evolving capability rather than a one-time project, organizations convert stability into competitive advantage: higher revenue per user, lower operating costs, and faster time-to-market for revenue-generating features. At A.M. Tech Consulting we translate SRE maturity into concrete profit metrics so leaders can prioritize investments that deliver measurable ROI.
Why SRE Maturity Drives Revenue
SRE maturity is a composition of interdependent pillars — performance, efficiency, and resilience — that together sustain and amplify the business value of engineering work. It’s critical to think of each aforementioned capability as an individual capability that work interdependently with the others. Each forms a hierarchy of foundations that need to occur to support the success of another layer. Each pillar maps directly to revenue levers:
Performance Revenue (Top-line uplift)
Faster load times and lower error rates increase conversion, session length, and customer lifetime value (CLTV).
Example metrics: improved conversion rate (%), increased average revenue per user (ARPU), reduced bounce rate.
Business impact: A 0.5–1.0 second reduction in median response time can yield single-digit percentage increases in conversion — directly boosting monthly recurring revenue (MRR).
Efficiency Savings (Cost and margin improvement)
Reducing incident-to-resolution time and lowering on-call load cuts mean lower operational expense (OpEx) and frees engineers to ship features.
Example metrics: reduction in mean time to recovery (MTTR), decrease in incident volume, developer productivity hours reclaimed.
Business impact: Reclaiming just 10% of engineering capacity can accelerate feature delivery by months, enabling earlier monetization and reducing time-to-value (TTV).
Resilience Growth (Scalable revenue expansion)
Scalable, highly available systems support growth into new geographies and customer segments with predictable cost-per-transaction.
Example metrics: availability percentage, successful autoscale events per load spike, cost-per-transaction under peak.
Business impact: Higher availability reduces churn and supports upsell/cross-sell strategies during high-demand windows.
How the Pillars Feed Continuous Improvement — and Profit
All pillars feed into improvement cycles: monitoring defines opportunities, incident analysis informs root-cause fixes, and automation institutionalizes gains. This cycle sustains performance improvements over time, maximizing ROI. A repeatable maturity model turns sporadic wins into compound returns:
Compound effect on revenue: Performance gains increase conversion; resilience prevents revenue leakage during peak events; efficiency enables faster delivery of monetizable features. Combined, these effects multiply ARR growth and operating margin expansion.
Investment prioritization: Treat SRE spend as strategic capex. By targeting high-impact gaps first, organizations achieve the fastest payback on reliability investments.
Assessment Deliverables That Translate to ROI
Our SRE maturity assessment gives leaders the data and action plan needed to connect SRE work to profit metrics.
Full SRE Readiness Report with maturity scores for each pillar.
Quantified maturity levels mapped to business KPIs (availability → churn reduction %, MTTR → cost savings, latency → conversion lift).
Baseline and projected improvements that feed into a pro forma revenue/cost model.
Gap Analysis showing where investments will yield the highest ROI.
Prioritized backlog of reliability initiatives ranked by expected net present value (NPV) and payback period.
ROI modeling for each initiative: projected incremental revenue, cost reductions, and impact on gross margin.
90-Day Action Plan to boost reliability and performance.
Tactical sprint-style roadmap with measurable milestones (e.g., reduce MTTR by X%, improve p95 latency by Y%).
Expected business outcomes per milestone: lift to ARPU, decrease in monthly OpEx, projected ARR acceleration.
Concrete Profit Metrics to Track Post-Assessment
Revenue-related:
Conversion lift (%) attributable to latency and error improvements.
Incremental MRR/ARR from reduced churn and improved conversion.
ARPU change after performance optimizations.
Cost-related:
OpEx saved from reduced incident toil and improved automation (USD/month).
Cost-per-transaction improvements during peak load (USD/transaction).
Engineering capacity reclaimed (FTE-equivalents) and its dollarized value.
Risk and value:
Expected revenue at risk prevented per major outage (USD/hour).
Payback period and ROI (%) for prioritized SRE initiatives.
NPV of a 12–36 month reliability investment portfolio.
Putting Assessment Results to Work — An Example Scenario
Baseline:
99.5% availability, 200 incidents/year, median response time 1.2s, ARPU $12.
Assessment recommendations:
Reduce incident volume by 30% via automation and error budgets.
Cut MTTR by 50% through improved runbooks and on-call tooling.
This snapshot of A.M. Tech Consulting’s SRE Maturity assessment identifies strengths, gaps, and the highest-impact opportunities to raise reliability, reduce downtime, and align engineering effort with business outcomes. At A.M. Tech Consulting (A.M.Tech) we translate these findings into tailored roadmaps, operational playbooks, and measurable implementation plans that scale with your organization. Contact us today to capture your SRE maturity, accelerate improvement, and turn reliability into a strategic advantage for your products and customers.